Una aplicación de análisis de Redes de Comercio Internacional
Author
Affiliation
Cantillan, R. | Bucca, M.
ISUC
Published
20 August 2024
1 Introducción
Este análisis se basa en el estudio de Luca De Benedictis y Lucia Tajoli (2011) sobre “La Red Mundial de Comercio” y utiliza datos del Proyecto “Correlates of War”. Exploraremos cómo el comercio internacional ha evolucionado a lo largo del tiempo, utilizando técnicas de análisis de redes y las herramientas proporcionadas por Tidyverse y Tidyr.
1.1 Datos
Los datos se encuentran en el archivo trade.csv y contienen la siguiente información:
country1: Nombre del país exportador
country2: Nombre del país importador
year: Año
exports: Valor total de las exportaciones (en decenas de millones de dólares)
Los datos cubren los años 1900, 1920, 1940, 1955, 1980, 2000 y 2009.
```{r}# dicotomizamos la red (en formato edgelist)# Iniciamos una cadena de operaciones sobre el dataframe 'trade'# El resultado final se asignará de vuelta a 'trade'trade <- trade %>%# Seleccionamos todas las columnas excepto '.row'# El signo menos (-) indica que estamos excluyendo esta columnaselect(-`.row`) %>%# Modificamos la columna 'exports':# Reemplazamos todos los valores NA en 'exports' con 0# Esto se hace usando la función replace_na()# Si hay otros valores en 'exports', se mantienen sin cambiosmutate(exports =replace_na(exports, 0))head(trade)```
country1
country2
year
exports
United States of America
Haiti
1900
0.00
United States of America
Dominican Republic
1900
0.00
United States of America
Mexico
1900
17.08
United States of America
Guatemala
1900
0.00
United States of America
Honduras
1900
0.00
United States of America
El Salvador
1900
0.00
3 Ejercicio 1: Análisis de densidad de red
Analizaremos el comercio internacional como una red no ponderada y dirigida. Crearemos una matriz de adyacencia donde \((i,j)\) es 1 si el país \(i\) exporta al país \(j\), y 0 en caso contrario.
La densidad de la red se define como:
\[
\text{densidad de la red} = \frac{\text{número de aristas}}{\text{número de aristas potenciales}}
\]
En el ejericio siguiente:
Identificamos todos los años únicos en los datos.
Preparamos la estructura de datos para almacenar resultados (densidades y matrices de adyacencia).
Para cada año:
Filtra los datos relevantes.
Crea una matriz de aristas (conexiones entre países).
Convierte esta matriz en un objeto de grafo.
Almacena el grafo.
Calcula y almacena la densidad del grafo.
El resultado final es una lista de grafos (adj.mat) y un vector de densidades (densities), uno para cada año en los datos.
Matrices de Adyacencia
Una matriz de adyacencia es una representación matemática de un grafo o red. En esta matriz, las filas y columnas representan los nodos (o vértices) del grafo, y los valores en la matriz indican si existe una conexión (arista) entre dos nodos.
Características principales:
Es una matriz cuadrada (mismo número de filas y columnas).
Para un grafo no dirigido, la matriz es simétrica.
Los elementos de la diagonal principal suelen ser cero (a menos que se permitan bucles).
Para grafos ponderados, los valores pueden representar el peso de las conexiones.
Ejemplo:
Consideremos un grafo simple con 3 nodos (A, B, C) y las siguientes conexiones:
Esta representación es útil para realizar cálculos y análisis sobre la estructura de la red.
El Loop: Procesamiento de Datos en Serie
Imagina un loop como una línea de producción para procesar datos:
```{r}# for (registro in base_de_datos) {# dato_limpio <- limpiar_dato(registro)# dato_analizado <- analizar_dato(dato_limpio)# almacenar_resultado(dato_analizado)# }```
Funcionamiento del Loop:
base_de_datos es tu conjunto de datos a procesar.
Cada registro es un elemento individual de la base de datos.
El loop procesa cada registro de forma secuencial.
Aplica las mismas operaciones (limpiar, analizar, almacenar) a cada registro.
Continúa hasta procesar todos los registros de la base de datos.
Este método es eficiente para aplicar un conjunto de operaciones a múltiples elementos de datos de manera sistemática.
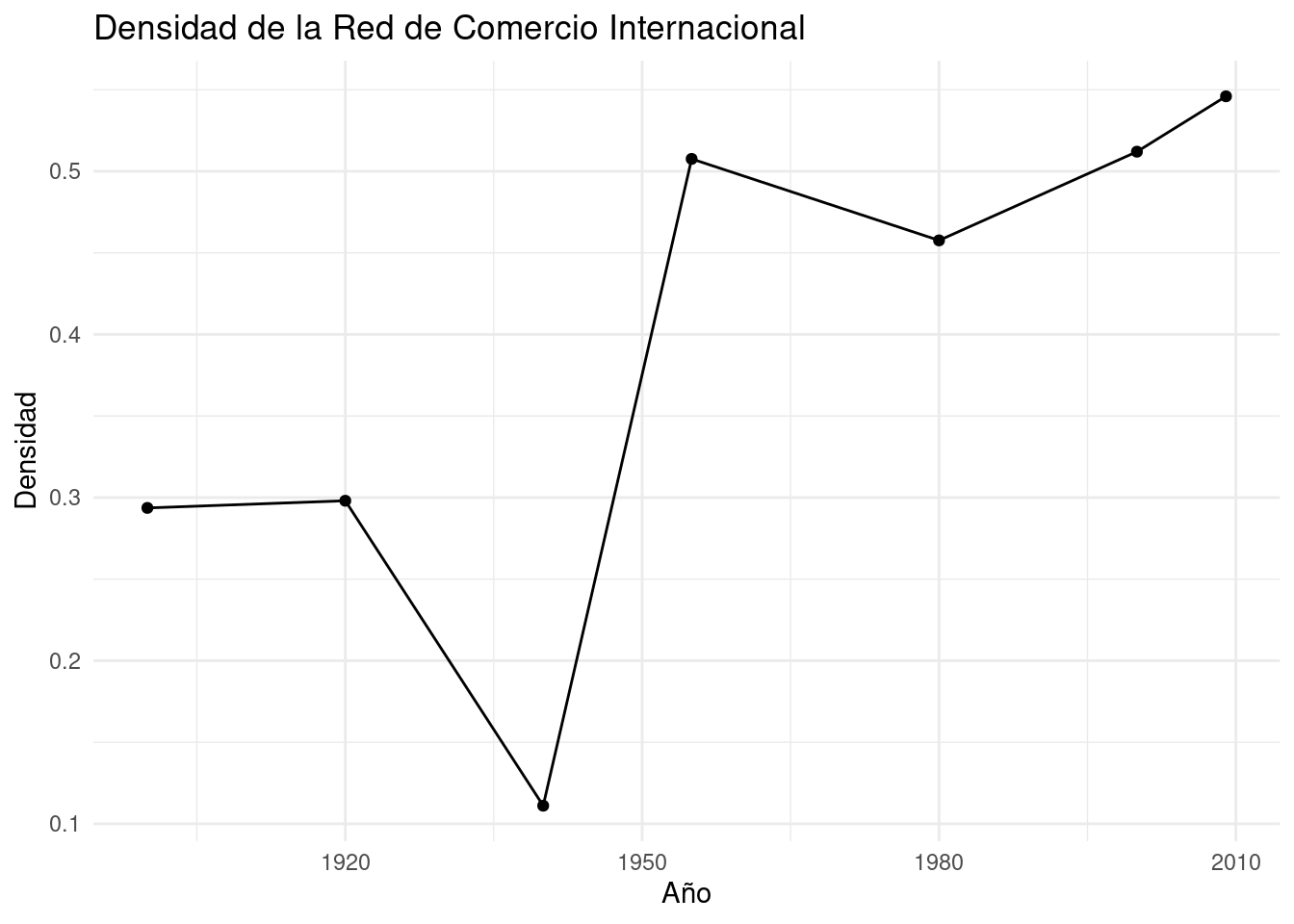
```{r}# Obtenemos todos los años únicos del conjunto de datos 'trade' y los guarda en 'years'years <-unique(trade$year)# Crea un vector 'densities' lleno de NA's, con la misma longitud que 'years'densities <-rep(NA, length(years))# Inicializa una lista vacía llamada 'adj.mat' para almacenar las matrices de adyacenciaadj.mat <-list()# Inicia un bucle que se ejecutará para cada año en 'years'for (i inseq_along(years)){# Filtra los datos de 'trade' para el año actual y exportaciones positivas,# selecciona solo los países exportador e importador, y convierte a matriz temp_edges <- trade %>%filter(year == years[i], exports >0) %>%select(country1, country2) %>%as.matrix()# Crea un objeto de grafo dirigido a partir de la matriz de aristas temp_adj <-graph_from_edgelist(temp_edges, directed =TRUE)# Guarda el grafo en la lista 'adj.mat' en la posición correspondiente al año actual adj.mat[[i]] <- temp_adj# Calcula la densidad del grafo y la guarda en 'densities' en la posición del año actual densities[i] <-graph.density(temp_adj)}# nombresnames(adj.mat) <- years# trasnformamos a tibbleplot_data <-tibble(year = years, density = densities)# ploteamos la distirbución ggplot(plot_data, aes(x = year, y = density)) +geom_line() +geom_point() +labs(title ="Densidad de la Red de Comercio Internacional",x ="Año", y ="Densidad") +theme_minimal()```
Interpretación: La densidad de la red de comercio internacional ha aumentado generalmente desde 1900 hasta 2009, lo que indica una creciente interconexión global. Sin embargo, se observa una caída notable alrededor de 1940, probablemente debido a las políticas proteccionistas y los efectos de la Segunda Guerra Mundial.
4 Ejercicio 2: Medidas de centralidad
Calcularemos las medidas de centralidad basadas en grado, intermediación y cercanía para los años 1900, 1955 y 2009.
La Función: Módulo de Análisis Reutilizable
Considera una función como un módulo de análisis especializado:
analizar_tendencias es el nombre de tu módulo de análisis.
datos, periodo, y variable son los parámetros de entrada.
La función ejecuta una serie de pasos analíticos predefinidos.
Procesa los datos de entrada según los parámetros especificados.
Retorna resultados estructurados (en este caso, una lista con la tendencia y un gráfico).
Se puede reutilizar para diferentes conjuntos de datos: analizar_tendencias(datos_ventas, "2023", "ingresos")
Esta estructura permite crear componentes de análisis modulares y reutilizables, lo cual mejora la eficiencia y consistencia.
```{r}# Definimos una función que calcula las medidas de centralidad para un año dadocalculate_centralities <-function(year) {# Obtiene el grafo correspondiente al año desde la lista adj.mat graph <- adj.mat[[as.character(year)]]# Crea un tibble con el país y sus medidas de centralidadtibble(country =names(V(graph)), # Nombres de los nodos (países)degree =degree(graph), # Grado de centralidadbetweenness =betweenness(graph), # Intermediacióncloseness =closeness(graph, mode ="all") # Cercanía ) %>%mutate(year = year) # Añade el año como columna}# Aplica la función a los años 1900, 1955 y 2009, combinando los resultados en un único dataframecentralities <-map_dfr(c(1900, 1955, 2009), calculate_centralities)# Muestra los 5 países con mayor grado de centralidad para cada añocentralities %>%group_by(year) %>%slice_max(n =5, order_by = degree) %>%# Selecciona los top 5 por gradoselect(year, country, degree, betweenness, closeness) %>%# Selecciona solo estas columnasarrange(year, desc(degree)) %>%# Ordena por año y grado descendente knitr::kable(caption ="Top 5 países por grado de centralidad") # Crea una tabla bonita```
Top 5 países por grado de centralidad
year
country
degree
betweenness
closeness
1900
United Kingdom
65
419.45519
0.0270270
1900
United States of America
54
133.10400
0.0238095
1900
France
47
60.04964
0.0217391
1900
Germany
47
63.79488
0.0222222
1900
Belgium
42
37.43019
0.0204082
1955
United Kingdom
151
296.91710
0.0123457
1955
German Federal Republic
147
210.47082
0.0121951
1955
Netherlands
146
138.47309
0.0121951
1955
Italy
146
244.81575
0.0121951
1955
France
145
153.91901
0.0120482
2009
United Kingdom
363
440.36355
0.0052083
2009
China
363
461.00904
0.0052356
2009
India
362
462.69186
0.0052356
2009
United States of America
361
521.24579
0.0052083
2009
France
361
414.56138
0.0052083
2009
Japan
361
473.51765
0.0052083
Interpretación: En los primeros períodos, los países occidentales (por ejemplo, Reino Unido, Alemania, Estados Unidos) tendían a dominar la red de comercio internacional en términos de centralidad. Para 2009, los cinco países principales se habían diversificado significativamente, con China e India ocupando posiciones destacadas.
La función map_dfr de purrr
La función map_dfr es parte de la familia de funciones map en el paquete purrr de R. Esta función es particularmente útil cuando se trabaja con listas o vectores y se desea aplicar una función a cada elemento, devolviendo los resultados como un único data frame.
Características principales:
Aplicación de función: Aplica una función dada a cada elemento de una lista o vector.
Combinación de resultados: Une los resultados de cada aplicación de la función en un único data frame.
Preservación de filas: El sufijo ’_dfr’ indica que los resultados se combinan por filas (row-binding).
Sintaxis básica:
map_dfr(.x, .f, ...)
Donde: - .x es la lista o vector de entrada - .f es la función a aplicar - ... son argumentos adicionales pasados a la función
map_dfr es especialmente útil en análisis de datos cuando se necesita aplicar la misma operación a múltiples conjuntos de datos y combinar los resultados en un único data frame para su posterior análisis o visualización.
5 Ejercicio 3: Análisis de red ponderada
Ahora analizaremos la red de comercio como una red ponderada y dirigida, donde el peso de cada arista es proporcional al volumen de comercio.
```{r}# Definimos una función para calcular centralidades ponderadas para un año específicocalculate_weighted_centralities <-function(year) {# Filtramos los datos para el año especificado, seleccionando solo conexiones con exportaciones > 0 edges <- trade %>%filter(year ==!!year, exports >0) %>%select(country1, country2, weight = exports)# Creamos un grafo dirigido a partir de los datos filtrados graph <-graph_from_data_frame(edges, directed =TRUE)# Calculamos las medidas de centralidad y las organizamos en un tibbletibble(country =names(V(graph)), # Nombres de los países (nodos)strength =strength(graph), # Fuerza (grado ponderado)betweenness =betweenness(graph, weights =E(graph)$weight), # Intermediación ponderadacloseness =closeness(graph, mode ="all", weights =E(graph)$weight) # Cercanía ponderada ) %>%mutate(year = year) # Añadimos el año como columna}# Aplicamos la función a los años 1900, 1955 y 2009weighted_centralities <-map_dfr(c(1900, 1955, 2009), calculate_weighted_centralities)# Mostramos los 5 países con mayor fuerza de centralidad para cada añoweighted_centralities %>%group_by(year) %>%slice_max(n =5, order_by = strength) %>%select(year, country, strength, betweenness, closeness) %>%arrange(year, desc(strength)) %>% knitr::kable(caption ="Top 5 países por fuerza de centralidad (red ponderada)")```
Top 5 países por fuerza de centralidad (red ponderada)
year
country
strength
betweenness
closeness
1900
United Kingdom
2836.4000
311.000000
0.0391651
1900
Germany
2081.9900
0.000000
0.0314140
1900
United States of America
1857.0103
184.000000
0.0438884
1900
France
1242.0400
44.000000
0.0255090
1900
Belgium
750.0987
300.000000
0.0439504
1955
United States of America
26285.5229
87.333333
0.0440882
1955
United Kingdom
15852.2630
78.000000
0.0461879
1955
German Federal Republic
11387.9900
78.000000
0.0379170
1955
Canada
9845.7020
119.333333
0.0580142
1955
France
6418.7470
0.000000
0.0549100
2009
United States of America
2550432.7900
0.000000
0.0001485
2009
China
2441328.3500
0.000000
0.0001489
2009
Japan
1182584.7600
0.000000
0.0001489
2009
France
867601.3080
187.379081
0.0001489
2009
United Kingdom
733534.1520
7.349355
0.0001489
Interpretación: Las medidas de centralidad para las redes ponderadas producen resultados sustancialmente diferentes de los de las redes no ponderadas. En particular, asignan puntuaciones altas de centralidad de intermediación y cercanía a países que no tienen grandes economías. Esto sugiere que, aunque estos países pueden no comerciar en grandes cantidades, conectan a otros grandes socios comerciales que de otro modo estarían distantemente conectados.
Grafos Dirigidos y su Representación Matricial
Un grafo dirigido es una estructura matemática que representa relaciones direccionales entre objetos.
Características principales:
Nodos (o vértices): Representan los objetos o entidades.
Aristas (o enlaces) dirigidos: Conectan los nodos y tienen una dirección específica.
5.1 Representación Matricial
Un grafo dirigido puede representarse mediante una matriz de adyacencia:
Es una matriz cuadrada de tamaño \(n \times n\), donde \(n\) es el número de nodos.
El elemento \(a_{ij}\) de la matriz es 1 si hay una arista del nodo \(i\) al nodo \(j\), y 0 en caso contrario.
Algebraicamente, para un grafo \(G\) con \(n\) nodos, su matriz de adyacencia \(A\) se define como:
\[
A = [a_{ij}] \quad \text{donde} \quad a_{ij} = \begin{cases}
1 & \text{si hay una arista de } i \text{ a } j \\
0 & \text{en caso contrario}
\end{cases}
\]
5.2 Ejemplo con R
Consideremos un pequeño grafo dirigido que representa el comercio entre 4 países:
library(igraph)# Definir las aristas del grafoedges <-matrix(c(1, 2, # País 1 exporta al País 21, 3, # País 1 exporta al País 32, 3, # País 2 exporta al País 33, 4# País 3 exporta al País 4), ncol =2, byrow =TRUE)# Crear el grafog <-graph_from_edgelist(edges, directed =TRUE)# Obtener la matriz de adyacenciaadj_matrix <-as_adjacency_matrix(g)# Mostrar la matriz de adyacenciaprint(adj_matrix)# Visualizar el grafoplot(g, edge.arrow.size =0.5, vertex.label =V(g)$name)
6 Ejercicio 4: Algoritmo PageRank
Aplicaremos el algoritmo PageRank a la red de comercio ponderada para cada año.
Algoritmo PageRank
El algoritmo PageRank, desarrollado por Larry Page y Sergey Brin en 1996, es un método para medir la importancia de los nodos en una red dirigida. Originalmente diseñado para clasificar páginas web en los resultados de búsqueda de Google, PageRank tiene aplicaciones en diversos tipos de redes, incluidas las redes de comercio internacional.
Definición formal:
Para un grafo dirigido \(G\) con n nodos, el PageRank \(PR(u)\) de un nodo u se define como: \[PR(u) = \frac{1-d}{n} + d \sum_{v \in B_u} \frac{PR(v)}{L(v)}\]
Donde:
\(d\) es un factor de amortiguación (típicamente 0.85) \(B_u\) es el conjunto de nodos que apuntan a u \(L(v)\) es el número de enlaces salientes desde el nodo v
En términos sustantivos, PageRank asigna una puntuación a cada nodo basándose en la estructura de enlaces de la red. Un nodo tiene un PageRank alto si:
Muchos otros nodos apuntan a él (tiene muchos enlaces entrantes)
Los nodos que apuntan a él también tienen un PageRank alto
En el contexto de redes de comercio internacional, un país con un alto PageRank sería uno que:
Recibe exportaciones de muchos otros países
Recibe exportaciones de países que a su vez son importantes en la red de comercio
Referencia:
Page, L., Brin, S., Motwani, R., & Winograd, T. (1999). The PageRank citation ranking: Bringing order to the web. Stanford InfoLab.
```{r}# Definimos una función para calcular PageRank para un año específicocalculate_pagerank <-function(year) {# Filtramos los datos para el año especificado# Seleccionamos solo las conexiones con exportaciones positivas# Renombramos 'exports' a 'weight' para usar en el grafo edges <- trade %>%filter(year ==!!year, exports >0) %>%select(country1, country2, weight = exports)# Creamos un grafo dirigido a partir de los datos filtrados graph <-graph_from_data_frame(edges, directed =TRUE)# Calculamos PageRank y creamos un tibble con los resultadostibble(country =names(V(graph)), # Nombres de los países (nodos del grafo)pagerank =page_rank(graph)$vector # Valores de PageRank para cada país ) %>%mutate(year = year) # Añadimos el año como columna}```
El operador de “unquoting” !! en rlang
En la expresión year == !!year:
year (el primer year) se refiere a la columna ‘year’ en el dataframe.
!!year (el segundo year) se refiere al argumento year de la función que contiene esta expresión.
El !! es un operador de “unquoting” en rlang, el lenguaje de metaprogramación de tidyverse. Su función es crucial en la programación con dplyr:
Propósito: Le indica a R que debe evaluar year en el entorno de la función, no en el dataframe.
Funcionamiento: “Desenvuelve” la variable year, insertando su valor en la expresión.
Necesidad: Sin !!, R buscaría una columna llamada year en el dataframe, lo cual no es lo deseado en este contexto.
Uso en programación: Permite crear funciones más flexibles que pueden trabajar con diferentes valores de variables.
Ejemplo:
filter_by_year <-function(data, year_val) { data %>%filter(year ==!!year_val)}
Aquí, !!year_val asegura que se use el valor pasado a year_val, no una columna llamada year_val.
Este operador es parte de la “programación no estándar” que hace que tidyverse sea poderoso y flexible para el análisis de datos.
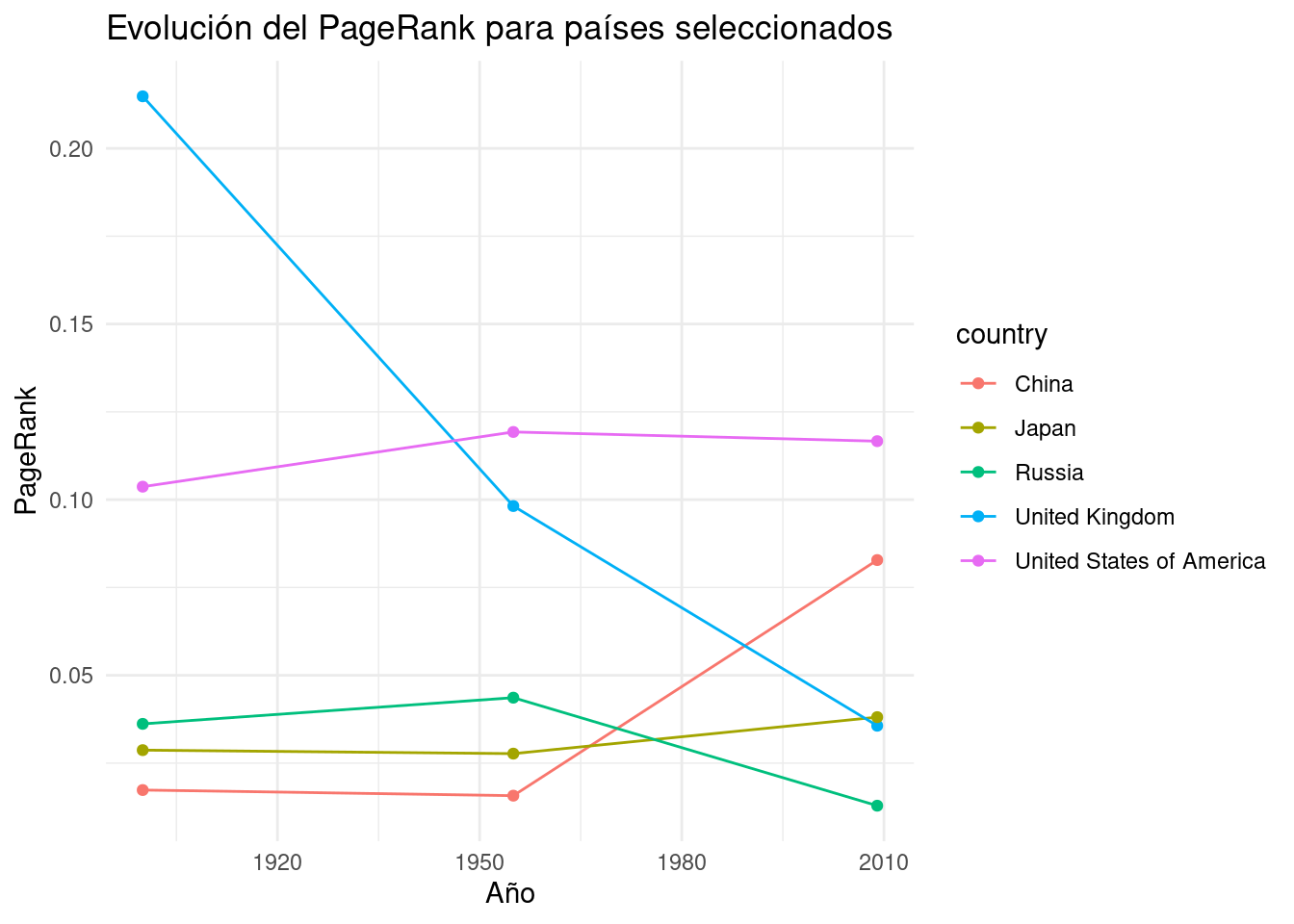
```{r}# Aplicamos la función a los años 1900, 1955 y 2009# map_dfr aplica la función a cada año y combina los resultados en un único dataframepagerank_results <-map_dfr(c(1900, 1955, 2009), calculate_pagerank)# Mostramos los 5 países con mayor PageRank para cada añopagerank_results %>%group_by(year) %>%# Agrupamos por añoslice_max(n =5, order_by = pagerank) %>%# Seleccionamos los top 5 por PageRankarrange(year, desc(pagerank)) %>%# Ordenamos por año y PageRank descendente knitr::kable(caption ="Top 5 países por PageRank") # Creamos una tabla formateada# Visualizamos la evolución del PageRank para países seleccionadospagerank_results %>%# Filtramos para incluir solo los países especificadosfilter(country %in%c("United States of America", "United Kingdom", "Russia", "Japan", "China")) %>%# Creamos un gráfico de líneasggplot(aes(x = year, y = pagerank, color = country)) +geom_line() +# Añadimos líneasgeom_point() +# Añadimos puntos para cada observaciónlabs(title ="Evolución del PageRank para países seleccionados",x ="Año", y ="PageRank") +theme_minimal() # Aplicamos un tema minimalista al gráfico```
Top 5 países por PageRank
country
pagerank
year
United Kingdom
0.2148234
1900
Germany
0.1241042
1900
United States of America
0.1036946
1900
France
0.0737686
1900
Belgium
0.0474671
1900
United States of America
0.1192706
1955
United Kingdom
0.0981821
1955
German Federal Republic
0.0619836
1955
Russia
0.0436273
1955
Canada
0.0414142
1955
United States of America
0.1166511
2009
China
0.0828028
2009
France
0.0405142
2009
Japan
0.0380871
2009
United Kingdom
0.0356402
2009
Interpretación: Estados Unidos ha tenido el PageRank más alto desde 1940. Antes de eso, el Reino Unido era el más influyente según el algoritmo PageRank. En los últimos años, las clasificaciones de Japón y luego de China han aumentado según los valores de PageRank, mientras que las clasificaciones de países como el Reino Unido y Rusia han disminuido.
7 Análisis de comunidades
Utilizaremos el algoritmo de detección de comunidades de Louvain para identificar grupos de países que comercian más entre sí.
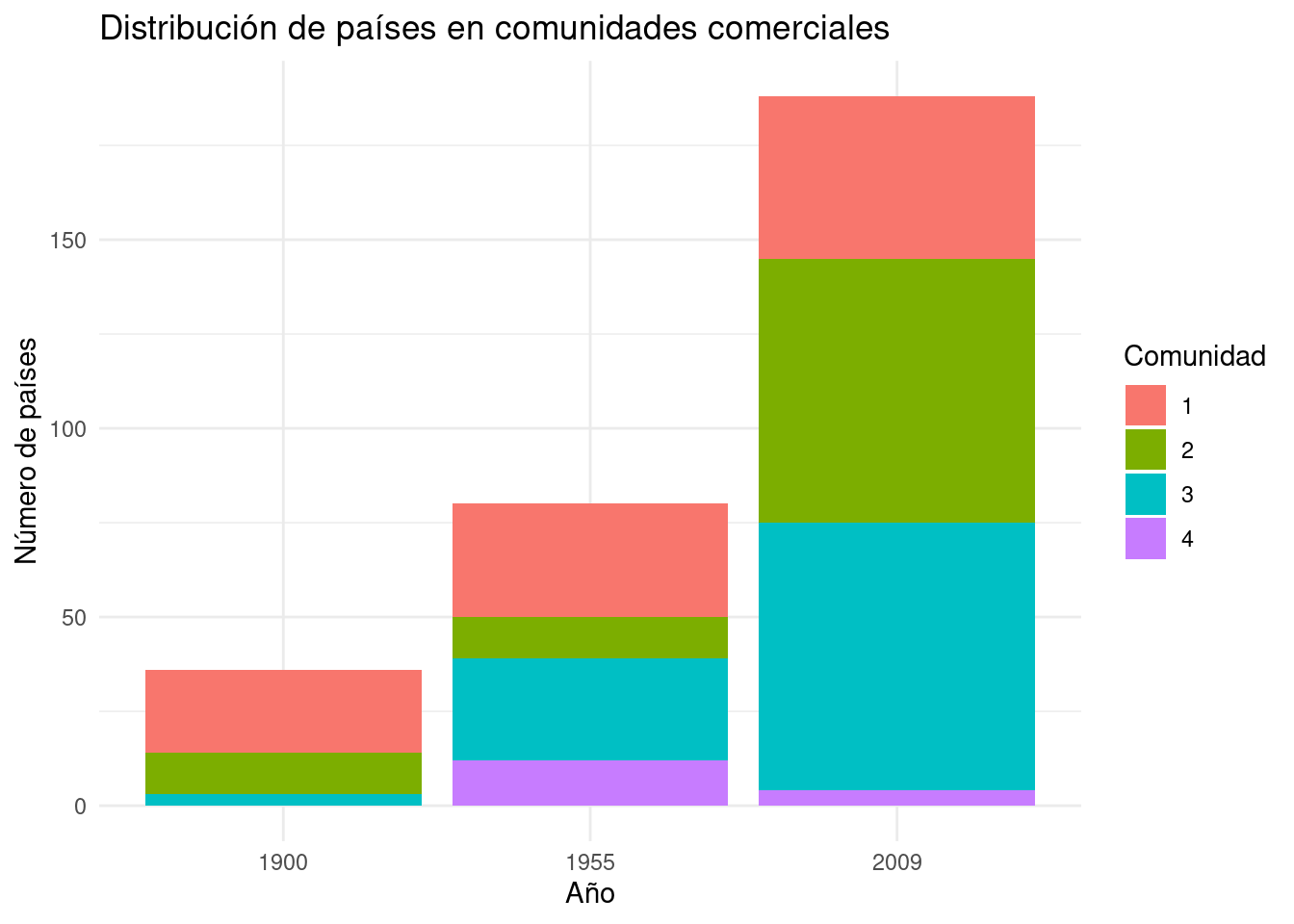
```{r}detect_communities <-function(year) { edges <- trade %>%filter(year ==!!year, exports >0) %>%select(country1, country2, weight = exports) graph <-graph_from_data_frame(edges, directed =TRUE) undirected_graph <-as.undirected(graph, mode ="collapse", edge.attr.comb =list(weight ="sum")) communities <-cluster_louvain(undirected_graph)tibble(country =names(V(undirected_graph)),community = communities$membership ) %>%mutate(year = year)}community_results <-map_dfr(c(1900, 1955, 2009), detect_communities)head(community_results, n=50)community_results %>%group_by(year, community) %>%summarise(count =n(), .groups ="drop") %>%ggplot(aes(x =factor(year), y = count, fill =factor(community))) +geom_bar(stat ="identity", position ="stack") +labs(title ="Distribución de países en comunidades comerciales",x ="Año", y ="Número de países", fill ="Comunidad") +theme_minimal()```
country
community
year
United States of America
1
1900
Haiti
1
1900
Dominican Republic
1
1900
Mexico
1
1900
Colombia
1
1900
Venezuela
1
1900
Ecuador
1
1900
Peru
1
1900
Brazil
1
1900
Bolivia
1
1900
Chile
1
1900
Argentina
1
1900
Uruguay
1
1900
United Kingdom
1
1900
Netherlands
1
1900
Belgium
1
1900
France
1
1900
Switzerland
2
1900
Spain
1
1900
Portugal
1
1900
Germany
2
1900
Austria-Hungary
2
1900
Italy
2
1900
Yugoslavia
2
1900
Greece
2
1900
Romania
2
1900
Russia
2
1900
Sweden
2
1900
Denmark
2
1900
Morocco
1
1900
Iran
2
1900
Turkey
1
1900
China
3
1900
Korea
3
1900
Japan
3
1900
Thailand
1
1900
United States of America
1
1955
Canada
1
1955
Cuba
1
1955
Haiti
1
1955
Dominican Republic
1
1955
Mexico
1
1955
Guatemala
1
1955
Honduras
1
1955
El Salvador
1
1955
Nicaragua
1
1955
Costa Rica
1
1955
Panama
1
1955
Colombia
1
1955
Venezuela
1
1955
```{r}alluvial_data <- community_results %>%group_by(year, community) %>%summarise(count =n(), .groups ="drop") %>%mutate(year =as.factor(year))# Calcular el total de países por año para los porcentajestotal_by_year <- alluvial_data %>%group_by(year) %>%summarise(total =sum(count))alluvial_data <- alluvial_data %>%left_join(total_by_year, by ="year") %>%mutate(percentage = count / total *100)head(alluvial_data)```
year
community
count
total
percentage
1900
1
22
36
61.111111
1900
2
11
36
30.555556
1900
3
3
36
8.333333
1955
1
30
80
37.500000
1955
2
11
80
13.750000
1955
3
27
80
33.750000
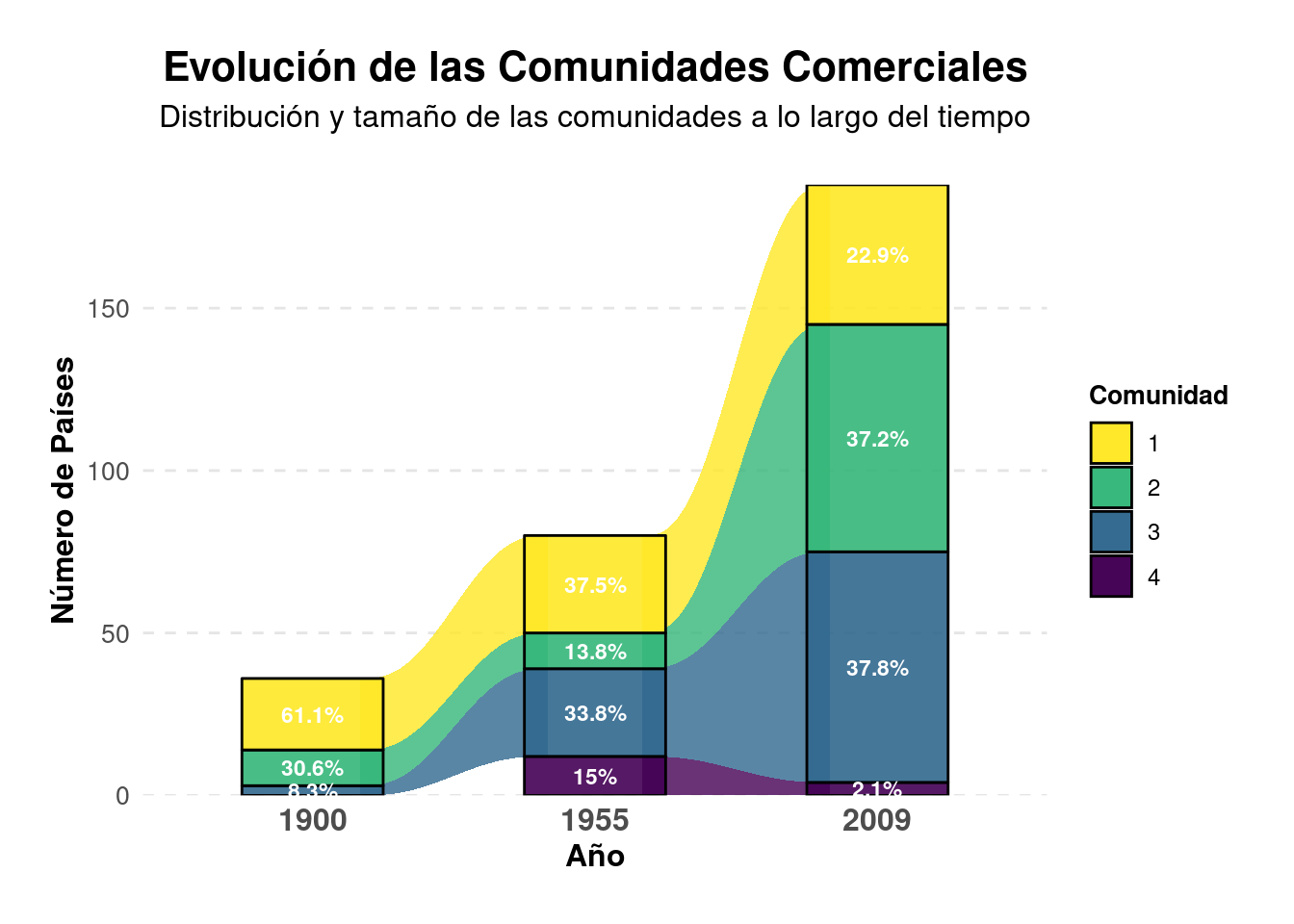
```{r}ggplot(alluvial_data,aes(x = year, y = count, alluvium = community, stratum = community)) +geom_flow(aes(fill =factor(community)), alpha =0.8, curve_type ="quintic") +geom_stratum(aes(fill =factor(community)), width =0.5, alpha =0.9) +geom_text(stat ="stratum", aes(label =paste0(round(percentage, 1), "%")), color ="white", size =3, fontface ="bold") +scale_fill_viridis_d(option ="D", direction =-1) +scale_y_continuous(expand =c(0, 0)) +labs(title ="Evolución de las Comunidades Comerciales",subtitle ="Distribución y tamaño de las comunidades a lo largo del tiempo",x ="Año",y ="Número de Países",fill ="Comunidad") +theme_minimal() +theme(legend.position ="right",axis.text.x =element_text(angle =0, hjust =0.5, size =12, face ="bold"),axis.text.y =element_text(size =10),axis.title =element_text(size =12, face ="bold"),plot.title =element_text(hjust =0.5, face ="bold", size =16),plot.subtitle =element_text(hjust =0.5, size =12, margin =margin(b =20)),panel.grid.major.x =element_blank(),panel.grid.minor =element_blank(),panel.grid.major.y =element_line(color ="gray90", linetype ="dashed"),legend.title =element_text(size =10, face ="bold"),legend.text =element_text(size =9),plot.margin =margin(t =20, r =20, b =20, l =20, unit ="pt") ) +guides(fill =guide_legend(title.position ="top", ncol =1))```
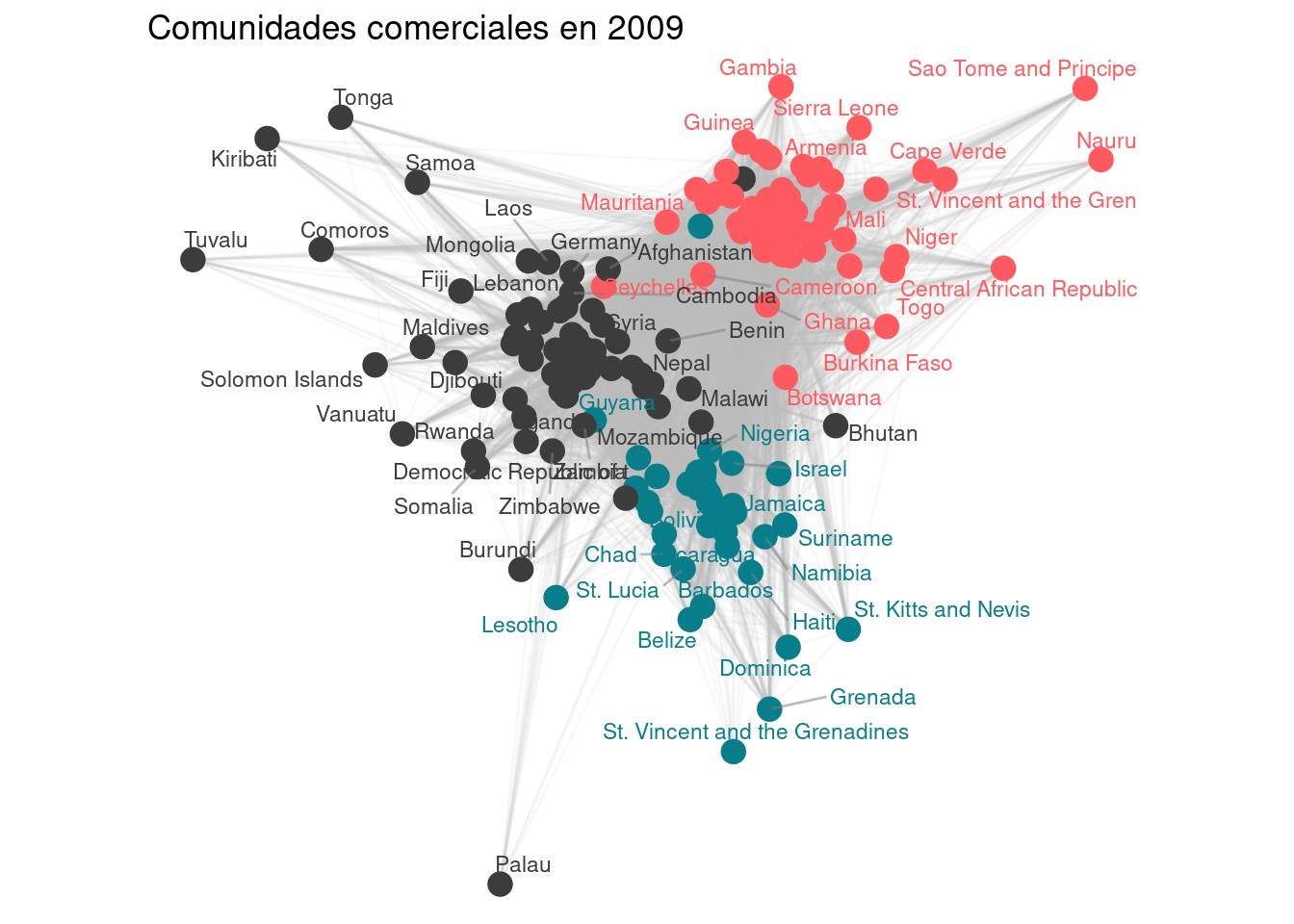
Interpretación: Este análisis nos permite identificar comunidades de países que tienden a comerciar más entre sí. Observando cómo estas comunidades cambian a lo largo del tiempo, podemos inferir cambios en los patrones globales de comercio, como la formación de bloques comerciales regionales o el surgimiento de nuevos centros de comercio global.
Intuición Teórica y Sociológica del Algoritmo de Detección de Comunidades
El algoritmo de Louvain, utilizado en este código para detectar comunidades, se basa en la optimización de la modularidad de la red. La modularidad es una medida que cuantifica la calidad de una división de la red en comunidades.
Formalmente, la modularidad Q se define como: \[Q = \frac{1}{2m} \sum_{ij} \left[A_{ij} - \frac{k_i k_j}{2m}\right] \delta(c_i, c_j)\] Donde:
\(A_{ij}\) es el peso de la arista entre los nodos i y j
\(k_i\) y \(k_j\) son las sumas de los pesos de las aristas adjuntas a los nodos i y j respectivamente
\(m\) es la suma de todos los pesos de las aristas en la red
\(c_i\) y \(c_j\) son las comunidades de los nodos i y j
\(\delta(c_i, c_j)\) es 1 si \(c_i = c_j\) y 0 en caso contrario
Intuitivamente, el algoritmo busca grupos de nodos que están más densamente conectados entre sí que con el resto de la red. En el contexto de redes de comercio internacional:
Bloques comerciales: Las comunidades detectadas pueden representar bloques comerciales o regiones económicas donde los países tienen relaciones comerciales más intensas entre sí.
Globalización vs. Regionalización: La evolución de estas comunidades a lo largo del tiempo puede reflejar tendencias hacia la globalización (menos comunidades, más interconectadas) o la regionalización (comunidades más definidas y separadas).
Asimetrías en el comercio global: La estructura de las comunidades puede revelar asimetrías en el sistema de comercio global, identificando grupos de países centrales y periféricos.
Impacto de políticas comerciales: Cambios en la estructura de las comunidades pueden reflejar el impacto de acuerdos comerciales, uniones aduaneras o cambios en las políticas económicas globales.
Resiliencia económica: La estructura de las comunidades puede ofrecer insights sobre la resiliencia de diferentes regiones económicas frente a shocks globales.
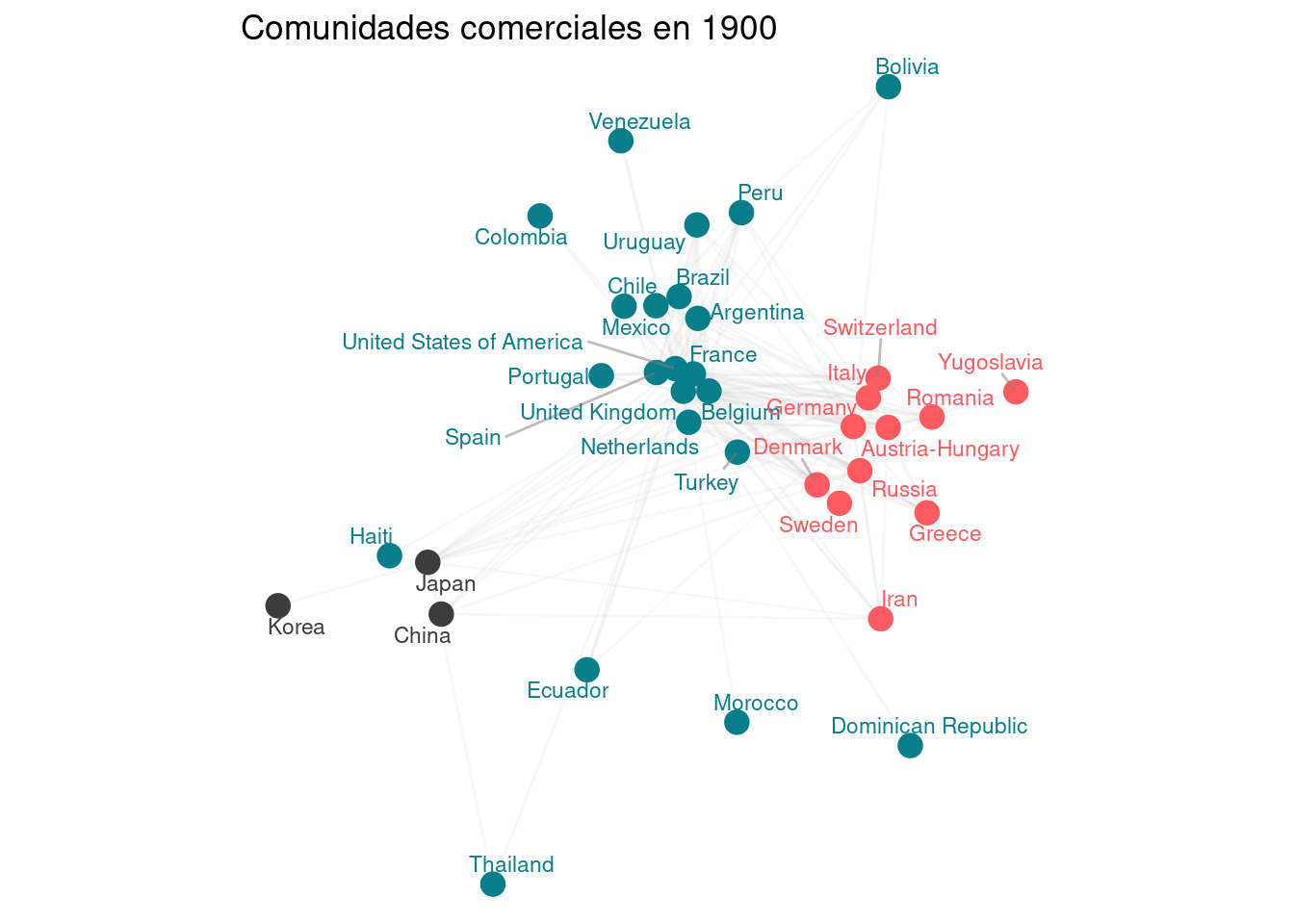
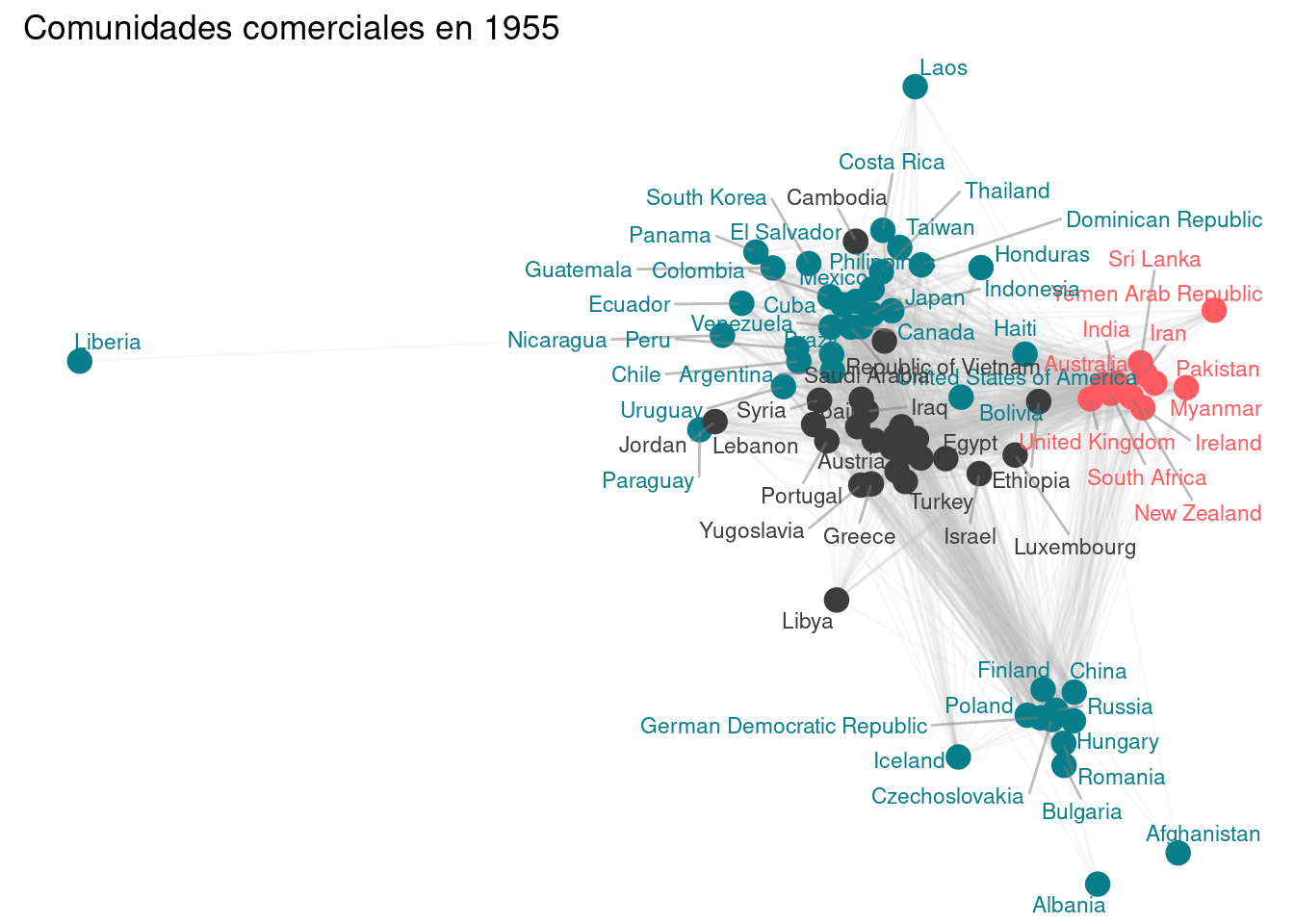
7.1 Network plots (EXTRA).
```{r}# Definición de la función para detectar comunidades en un año específicodetect_communities <-function(year) {# Filtrar los datos para el año específico y seleccionar columnas relevantes edges <- trade %>%filter(year ==!!year, exports >0) %>%select(country1, country2, weight = exports)# Crear un grafo dirigido a partir de los datos filtrados graph <-graph_from_data_frame(edges, directed =TRUE)# Convertir el grafo dirigido en no dirigido, sumando los pesos de las aristas undirected_graph <-as.undirected(graph, mode ="collapse", edge.attr.comb =list(weight ="sum"))# Detectar comunidades utilizando el algoritmo de Louvain communities <-cluster_louvain(undirected_graph)# Devolver una lista con el grafo no dirigido y las comunidades detectadaslist(graph = undirected_graph,communities = communities )}# Definición de la función para crear y optimizar el plot de comunidadesplot_community_optimized <-function(year) {# Detectar comunidades para el año especificado result <-detect_communities(year) graph <- result$graph communities <- result$communities# Crear un layout inicial utilizando el algoritmo Fruchterman-Reingold layout_initial <-layout_with_fr(graph)# Función para calcular el centro de una comunidad community_center <-function(comm) { members <-which(communities$membership == comm)colMeans(layout_initial[members,, drop =FALSE]) }# Calcular los centros de todas las comunidades comm_centers <-sapply(unique(communities$membership), community_center)# Ajustar el layout para agrupar nodos por comunidad layout_adjusted <- layout_initialfor (comm inunique(communities$membership)) { members <-which(communities$membership == comm) center <- comm_centers[,comm]# Mover los nodos hacia el centro de su comunidad (70% hacia el centro, 30% posición original) layout_adjusted[members,] <- layout_initial[members,, drop =FALSE] *0.3+matrix(center, nrow =length(members), ncol =2, byrow =TRUE) *0.7 }# Normalizar el layout ajustado layout_normalized <-scale(layout_adjusted)# Crear un dataframe con la información de los nodos node_data <-tibble(name =V(graph)$name,community = communities$membership,x = layout_normalized[,1],y = layout_normalized[,2] )# Crear un dataframe con la información de las aristas edge_data <-as_tibble(get.edgelist(graph)) %>%rename(from = V1, to = V2) %>%left_join(node_data, by =c("from"="name")) %>%left_join(node_data, by =c("to"="name"), suffix =c("_from", "_to"))# Definir los colores específicos para las comunidades color_palette <-c("#087e8b", "#ff5a5f", "#3c3c3c")# Asignar colores a las comunidades, repitiendo si es necesario num_communities <-length(unique(communities$membership)) community_colors <-rep_len(color_palette, num_communities)# Crear el gráfico con ggplot2ggplot() +# Dibujar las aristas como segmentos grises semi-transparentesgeom_segment(data = edge_data, aes(x = x_from, y = y_from, xend = x_to, yend = y_to),alpha =0.1, color ="gray") +# Dibujar los nodos como puntos coloreados por comunidadgeom_point(data = node_data, aes(x = x, y = y, color =factor(community)), size =4) +# Añadir etiquetas de texto repelentes para los nombres de los paísesgeom_text_repel(data = node_data, aes(x = x, y = y, label = name, color =factor(community)), size =3, max.overlaps =20, segment.color ="gray50", segment.alpha =0.5) +# Aplicar la paleta de colores personalizadascale_color_manual(values = community_colors) +# Usar un tema vacío para el fondotheme_void() +# Mantener la proporción de los ejescoord_fixed() +# Añadir título al gráficolabs(title =paste("Comunidades comerciales en", year),color ="Comunidad") +# Ocultar la leyendatheme(legend.position ="none")}# Crear gráficos para cada año de interésplot_1900 <-plot_community_optimized(1900)plot_1955 <-plot_community_optimized(1955)plot_2009 <-plot_community_optimized(2009)# Mostrar los gráficosprint(plot_1900)print(plot_1955)print(plot_2009)```